DiffRhythm AI
VisitProduct Information
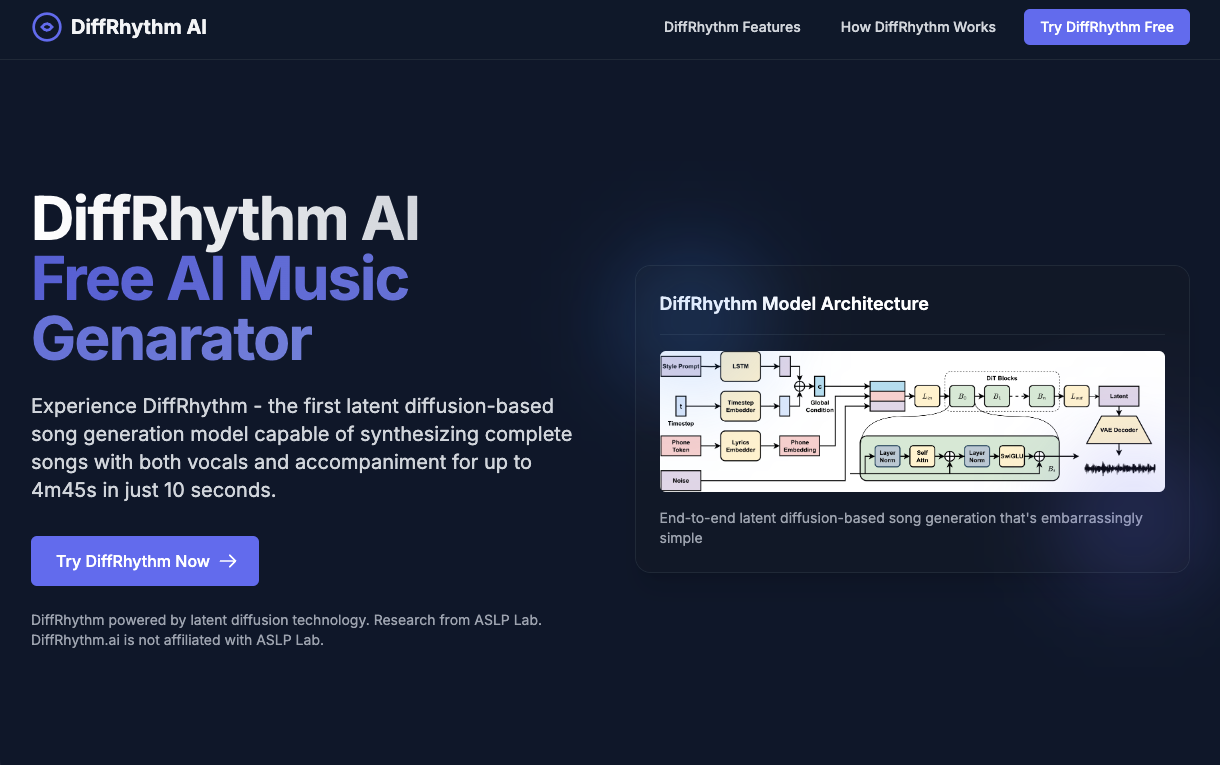
DiffRhythm AI lets you create complete songs with both vocals and accompaniment in seconds using latent diffusion technology. Generate full-length music from just lyrics and style prompts.
Added on March/10
DiffRhythm AI Feature
Blazingly Fast
Generate full-length songs of up to 4m45s in just 10 seconds, thanks to our non-autoregressive structure that ensures rapid inference speeds.
Complete Songs
Create songs with both vocals and accompaniment in a single pass, eliminating the need for separate models or complex multi-stage architectures.
Embarrassingly Simple
Enjoy a straightforward model structure that eliminates complex data preparation and requires only lyrics and a style prompt during inference.
High Musicality
Generate songs with high musicality and intelligibility, creating professional-sounding music across diverse genres and styles.
Style Control
Control the musical style with simple text prompts, allowing you to generate music in various genres from rock to pop, classical to jazz.
Scalable Architecture
Benefit from a scalable architecture that can be trained on larger datasets, enabling continuous improvement and expansion of capabilities.
Browse AI Tools Similar to DiffRhythm AI
DiffRhythm AI Reviews
What do you think about DiffRhythm AI?
Leave a review for the community
This tool does not have any reviews yet. Be the first to review it.